※1点の税込金額となります。 複数の商品をご購入いただいた場合のお支払金額は、 単品の税込金額の合計額とは異なる場合がございますので、予めご了承ください。
本書は、Splunkを使ったデータ分析の解説書です。
効率的な前処理から機械学習までを扱い、
Splunk上で機械学習を実現するMLTKを丁寧に解説しています。
各章は機械学習の概念に始まり、データ分析をする上で必要な基礎知識、
Splunkを用いたデータの可視化、データ加工方法の紹介から
実際にサンプルケースを用いた分析とその解説で構成されています。
Splunkを用いてデータ分析・機械学習に取り組みたい人には必読の1冊です。
【こんな方にお勧めします】
・Splunkを使っているが、SPLの書き方に困っている方
・Splunkでの効果的なデータの可視化の方法を知りたい方
・Splunkでの機械学習の方法を知りたい方
【目次】
第1章 Splunkについて
第2章 機械学習の流れ
第3章 Splunk・MLTKによる機械学習
第4章 Splunkへデータ登録するまでの基本的な手続き
第5章 特徴量を生成するための前処理と手法
第6章 Splunkによる特徴量評価
第7章 機械学習の実演

本書は、Splunkを使ったデータ分析の解説書です。効率的な前処理から機械学習までを扱い、Splunk上で機械学習を実現するMLTKを丁寧に解説しています。各章は機械学習の概念に始まり、データ分析をする上で必要な基礎知識、Splunkを用いたデータの可視化、データ加工方法の紹介から実際にサンプルケースを用いた分析とその解説で構成されています。Splunkを用いてデータ分析・機械学習に取り組みたい人には必読の1冊です。

より理解しやすいよう、本書では下記の要素を随所に入れています
・Point
紹介している内容で特に重要な点について述べています。
・Caution
Splunkの操作上の注意点や、つまずきやすい内容を述べています。
・Column
内容を理解するのに必須ではありませんが、本書をより理解して読み進めるために知っていると役に立つ内容を紹介しています。
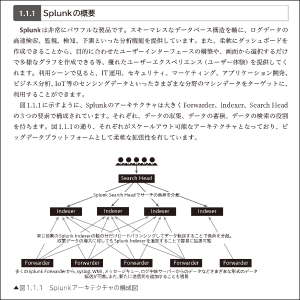
第1章ではSplunk製品の紹介と環境構築を述べています。第2章と第3章では、機械学習の概要からSplunkで利用できる学習アルゴリズムを紹介しています。第6章では、データ分析で必要となる、データ評価観点について述べています。
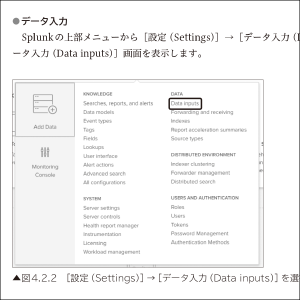
第4章ではSplunkにおけるデータ管理からデータの登録方法を紹介しています。第5章では第4章で取り込んだデータを用いて、データ加工のテクニックを目的別に述べています。

第7章では本書の理解のまとめとして、オープンデータを用いて実際に実習しています。
第1章 Splunkについて
1.1 Splunkの導入
1.1.1 Splunkの概要
1.1.2 Splunk環境の構築(Windows版)
1.2 MLTKの概要と導入
1.2.1 MLTKとは
1.2.2 MLTKの導入
1.2.3 Splunkのデータ検索について
第2章 機械学習の流れ
2.1 機械学習とは
2.1.1 人工知能と機械学習
2.1.2 機械学習の種類と概要
2.1.3 教師あり学習
2.1.4 教師なし学習
2.2 学習から評価までの流れ
2.2.1 機械学習の手続き
2.2.2 特徴量と特徴量エンジニアリング
2.2.3 学習モデルの生成と推論
2.2.4 モデルの精度評価と評価指標
第3章 Splunk・MLTKによる機械学習
3.1 利用できるアルゴリズム概要
3.1.1 MLTKで利用可能な主なアルゴリズム一覧
3.1.2 アルゴリズムの選択時のポイント
3.2 利用できるアルゴリズムとSPLについて
3.2.1 線形回帰
3.2.2 ラッソ回帰・リッジ回帰
3.2.3 ロジスティック回帰
3.2.4 ナイーブベイズ(単純ベイズ分類器)
3.2.5 ランダムフォレスト
3.2.6 ARIMA
3.2.7 k-means/x-means
3.2.8 DBSCAN
3.3 Splunkを用いた精度評価
3.2.1 Splunkで利用できる評価指標
3.2.2 regressionstatistics
3.2.3 confusionmatrix
3.2.4 classificationstatistics
第4章 Splunkへデータ登録するまでの基本的な手続き
4.1 Splunkにおける機械学習環境の準備
4.1.1 Splunkにおけるデータ操作の前準備の流れ
4.1.2 第4章で使用するデータについて
4.2 インデックス(Index)の作成
4.2.1 ソースタイプ(Source type)とバケツ(Bucket)について
4.2.2 Source type定義の流れ
4.2.3 Index作成の流れ
4.3 フィールドの抽出
4.3.1 Splunkにおけるフィールド抽出設定とは
4.3.2 フィールド抽出の手続き
4.4 マスタ情報のLookup登録
4.4.1 ルックアップ(Lookup)とは
4.4.2 ルックアップ(Lookup)に登録する手続き
4.5 基本的なデータ操作について
4.5.1 基本的なサーチコマンド
4.5.2 whereコマンド
4.5.3 evalコマンド
4.5.4 statsコマンド
4.5.5 サブサーチ
4.6 データモデル高速化による高速集計
4.6.1 データモデル高速化とは
4.6.2 データモデル高速化の方法
4.6.3 tstatsコマンドを用いた高速集計
4.6.4 statsコマンドとの速度比較
第5章 特徴量を生成するための前処理と手法
5.1 時間データに関する処理
5.1.1 文字列を時間形式に変換する
5.1.2 UNIX時間を日付形式の文字列に変換する
5.1.3 時間要素を加算・減算する
5.1.4 時間情報をカテゴリ化する
5.2 数量データに関する処理
5.2.1 階差を算出する
5.2.2 数量を正規化する
5.2.3 数量を標準化する
5.2.4 数量を離散化(グルーピング)する
5.2.5 移動平均を算出する
5.3 文字列データに関する処理
5.3.1 位置を指定して文字列を切り出す
5.3.2 文字列を連結する
5.3.3 文字列から不要な文字を取り除く
5.3.4 大小文字を統一する
5.3.5 文字列を置換する
5.3.6 さまざまな文字列値をカテゴリに集約する
5.3.7 さまざまな文字列から一部分を抽出する
5.3.8 カテゴリ文字列をフラグ化(ONE-HOT化)する
5.3.9 テキストデータを類似度でグルーピングする
5.4 IPアドレスデータに関する処理
5.4.1 IPアドレスから地理情報を取得する
5.4.2 IPアドレスが特定のネットワークに含まれるか判定する
5.5 データセットの集約
5.5.1 データをフィールドの値で集約する
5.5.2 データを時間で集約する
5.5.3 データを柔軟に区切って集約する
5.6 その他の前処理
5.6.1 欠損値を補間する
5.6.2 データをサンプリングする
5.6.3 サーチ結果をマスタ情報と結合する
5.6.4 IDを付与する
5.6.5 特徴量を削減する(次元圧縮)
第6章 Splunkによる特徴量評価
6.1 機械学習における特徴量評価の重要性
6.1.1 機械学習における特徴量評価の重要性
6.1.2 特徴量評価における図示の重要性
6.2 特徴量評価における確認すべき着眼点
6.2.1 特徴量評価のための可視化手法
6.2.2 相関性と線形性・独立性
6.2.3 線形性、独立性の評価
6.2.4 正規性
6.2.5 正規性の評価
6.2.6 等分散性
6.2.7 等分散性の評価
6.2.8 分離性
6.2.9 分離性の評価
6.2.10 均質性
6.2.11 規則性
6.3 Splunkを用いた特性評価
6.3.1 ヒストグラムと箱ひげ図の作成、分析
6.3.2 散布図の作成、分析
6.3.3 複数のヒストグラム・箱ひげ図の作成、分析
6.3.4 マトリクス散布図の作成、分析
6.3.5 主成分分析結果からの特徴量評価
6.3.6 相関係数の算出および相関表の作成
第7章 機械学習の実演
7.1 分類モデルの作成
7.1.1 分類問題と扱うサンプルデータについて
7.1.2 データの概要把握
7.1.3 特徴量加工
7.1.4 特徴量の評価
7.1.5 学習モデルの作成・適用・評価
7.2 回帰モデルの作成
7.2.1 サンプルデータについて
7.2.2 データの概要把握
7.2.3 特徴量加工(文字列のカテゴリ集約)
7.2.4 特徴量加工(外れ値除外)
7.2.5 特徴量加工(欠損値補間)
7.2.6 特徴量加工(originのONE-HOT化)
7.2.7 特徴量加工(非正規分布の補正)
7.2.8 特徴量加工(数量の標準化)
7.2.9 特徴量の評価
7.2.10 学習モデルの作成・適用・評価

[特集]テキスト生成、画像生成、動画生成など、生成AI活用のスキルが身…

[特集]ビジネスマナー、仕事術を身に付けるならこの一冊!おすすめビジネ…

[キャンペーン]ポイント還元率もUP!紙版とPDF版を併用したい方にお…

[特集]Microsoft認定試験対策ならMCP教科書!信頼と実績の赤…

[特集]スキマ時間で稼ぎたい人に!自分の好きな時間に働ける副業や株式投…

[特集]入門書から専門書まで、人工知能関連のおすすめ本をご紹介!
お気に入りに登録すると、気になる商品ページにすばやくアクセスできます。ご利用にはログインが必要です。








