Brett Lantz(著) , 株式会社クイープ(翻訳) , 株式会社クイープ(監修)
※1点の税込金額となります。 複数の商品をご購入いただいた場合のお支払金額は、 単品の税込金額の合計額とは異なる場合がございますので、予めご了承ください。
【本書の内容】
本書は
Brett Lantz, "Machine Learning with R - Third Edition",
Packt Publishing, 2019
の邦訳版です。
本書は「機械学習」で語られることの多い手法(最近傍法や回帰法、ナイーブベイズ
や決定木を使った分類法)を網羅し、それぞれの意味や成立条件を解説します。
といっても、ゴリゴリの数式だけを使うわけではなく、既存のデータを使用し、
それら手法によって解析した結果、どのようなグラフが表示されるか、を
手取り足取りで解説してくれます。
ですから、機械学習を構成するさまざまな手法を、実際に使えるレベルで理解できる
ようになります。
そのため、自身が関わるプロジェクトにおいて、どの手法がベストプラクティスと
なるのか、無意味な分析・解析を避ける勘所がわかるようになるでしょう。
「機械学習」を学んだものの「もやもや」に付きまとわれているエンジニアに
よく効く一冊です。
【本書のポイント】
・「機械学習」と呼ばれる手法を網羅
・手法を構成する手続きやその前準備を微細に解説
・各手法のメリットとデメリットも紹介
・実際に手を動かすことで各種手法を正しく利用できるようになる
【読者が得られること】
・機械学習とその派生手法のモデルを頭の中に構築できる
・機械学習を成立させるさまざまな手法に精通できる
・プロジェクトで真に必要な手法がわかる
・(ついでに)R言語(4.x系)も習得できる
【著者について】
・Brett Lantz(ブレット・ランツ)
社会学者として教育を受けた著者は、人間の行動を理解するために10年以上に
わたってイノベーティブなデータ手法を活用してきた。
DataCampの講師であり、世界中の機械学習カンファレンスやワークショップで
たびたび講演を行っている。

本書は『Brett Lantz, "Machine Learning with R - Third Edition",Packt Publishing, 2019』の邦訳版です。
機械学習の中心には、情報を意思決定に活かせる知識に変えるアルゴリズムがあります。このため、機械学習はこのビッグデータ時代にぴったりです。機械学習がなければ、とめどなく流れる情報を追いかけることはとてもできないでしょう。Rはクロスプラットフォームでコストのかからない統計学的プログラミング環境であり、その存在感が増していることを考えると、機械学習を始めるのに絶好のタイミングです。Rが提供するツールは強力でありながら習得しやすいため、データから知見を見つけ出すのに貢献するでしょう。本書では、内部の仕組みを理解するために必要な基本的な理論に実践的なケーススタディを組み合わせることで、機械学習への取り組みを開始するのに必要な知識をすべて提供します。
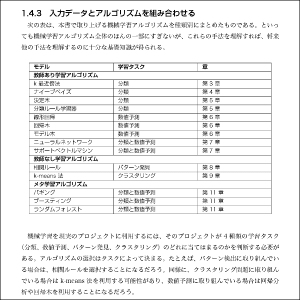
機械学習のさまざまな学習器を定義および区別している用語や概念に加えて、学習タスクに適切なアルゴリズムをマッチさせる方法を紹介します。

Rを使ってデータを実際に操作する機会を提供し、データを読み込み、調査し、理解するための基本的なデータ構造と手続きについて説明します。
単純ながら強力な機械学習アルゴリズムを理解し、悪性腫瘍の識別という最初の現実的なタスクにどのように適用すればよいかを示します。

最先端のスパムフィルタリングシステムで使われている基本的な確率の概念を明らかにします。独自のスパムフィルタを構築しながらテキストマイニングの基礎を学びます。
正確なだけではなく簡単に説明できる予測値を生成する学習アルゴリズムを2つ取り上げます。そして、透明性が重視されるタスクにこれらのアルゴリズムを適用します。

数値を予測するための機械学習アルゴリズムを紹介します。これらの手法は統計学と深く結び付いているため、数値的な関係を理解するのに必要な、基本的な指標も取り上げます。

複雑ながら強力な機械学習アルゴリズムを2つ取り上げます。これらのアルゴリズムで使われている数学が難しく感じられるかもしれませんが、例を交えながら、それらの内部の仕組みをわかりやすい言葉で説明します。
多くの小売業者が導入しているレコメンデーションシステムで使われているアルゴリズムを取り上げます。小売業者のほうが自分の購入習慣をよく知っているように感じたことはないでしょうか。この章では、その秘密が明らかになります。
関連するアイテムをクラスタ化する方法について説明します。そして、オンラインコミュニティのプロフィールの特定にこのアルゴリズムを利用します。

機械学習プロジェクトの成否を評価する方法と、未知のデータに対する学習器の性能を信頼できる推定値として取得する方法について説明します。

機械学習コンテストの上位チームが採用している手法を明らかにします。コンテストに参加したい場合、あるいはデータからできるだけ多くの価値を引き出したいだけあっても、これらの手法をレパートリーに加える必要があるでしょう。

ビッグデータからRの高速化まで、機械学習の最前線を探ります。これらのトピックはRでできることの限界を押し広げるのに役立つでしょう。
第1章 機械学習入門
1.1 機械学習の起源
1.2 機械学習の利用と乱用
1.3 機械はどのように学習するか
1.4 実際の機械学習
1.5 Rによる機械学習
1.6 まとめ
第2章 データを管理し、理解する
2.1 Rのデータ構造
2.2 Rでのデータの管理
2.3 データを調べて理解する
2.4 まとめ
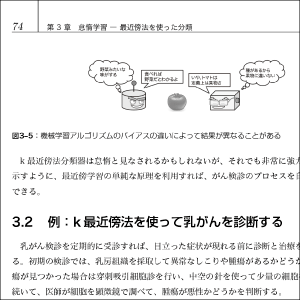
第3章 怠惰学習―最近傍法を使った分類
3.1 最近傍法分類を理解する
3.2 例:k最近傍法を使って乳がんを診断する
3.3 まとめ
第4章 確率論的学習―ナイーブベイズを使った分類
4.1 ナイーブベイズを理解する
4.2 例:ナイーブベイズを使ってSMSスパムをフィルタリングする
4.3 まとめ
第5章 分割統治―決定木と分類ルールに基づく分類
5.1 決定木を理解する
5.2 例:C5.0の決定木を使ってあぶない融資を特定する
5.3 分類ルールを理解する
5.4 例:分類ルール学習器を使って毒キノコを識別する
5.5 まとめ
第6章 数値データを予測する―回帰法
6.1 回帰を理解する
6.2 例:線形回帰を使って医療費を予測する
6.3 回帰木とモデル木を理解する
6.4 例:回帰木とモデル木を使ってワインの品質を予測する
6.5 まとめ
第7章 ブラックボックス手法―ニューラルネットワークとサポートベクトルマシン
7.1 ニューラルネットワークを理解する
7.2 例:人工ニューラルネットワークを使ってコンクリートの強度をモデル化する
7.3 サポートベクトルマシンを理解する
7.4 例:SVMを使って文字を認識する
7.5 まとめ
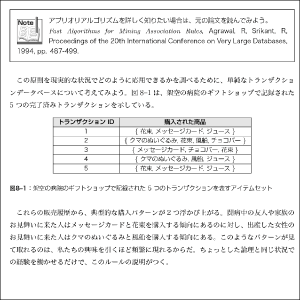
第8章 パターン検出―相関ルールを使ったバスケット分析
8.1 相関ルールを理解する
8.2 例:相関ルールを使って頻繁に購入される商品を特定する
8.3 まとめ
第9章 データのグループを特定する―k-means法
9.1 クラスタリングを理解する
9.2 例:k-means法を使ってマーケティングセグメントを特定する
9.3 まとめ
第10章 モデルの性能を評価する
10.1 分類の性能を計測する
10.2 将来の性能を推定する
10.3 まとめ
第11章 モデルの性能を改善する
11.1 定番のモデルの性能を向上させる
11.2 メタ学習でモデルの性能を改善する
11.3 まとめ
第12章 機械学習の専門的なトピック
12.1 現実のデータの管理と前処理
12.2 オンラインデータとオンラインサービスの操作
12.3 問題領域固有のデータを操作する
12.4 Rの性能を向上させる
12.5 まとめ

[キャンペーン]【7/22まで】最大70%ポイント還元! 夏のPDF版…

[特集]翔泳社のプログラミング書籍の中から、入門・初級者向けの書籍をピ…

[キャンペーン]ポイント還元率もUP!紙版とPDF版を併用したい方にお…

[特集]Pythonのおすすめ本を入門~上級までレベル別・目的別にご紹…

[特集]令和の新しい学習術や、「図解・視覚化の技術」、AIやフレームワ…

[特集]保育士を目指している方にも、すでに保育現場で働き始めている方に…
お気に入りに登録すると、気になる商品ページにすばやくアクセスできます。ご利用にはログインが必要です。









