本書は、Pythonでプログラミングをした経験のある読者が、
各種オープンソースソフトウェア(OSS)やライブラリを利用して、
自然言語処理を行うWebアプリケーションを作って動かし、
自然言語処理を体験するための書籍です。
またその中で、自然言語処理に関連するさまざまな概念や手法、
簡単な理論についても学ぶことができ、本格的な学習の
前段階としても最適です。
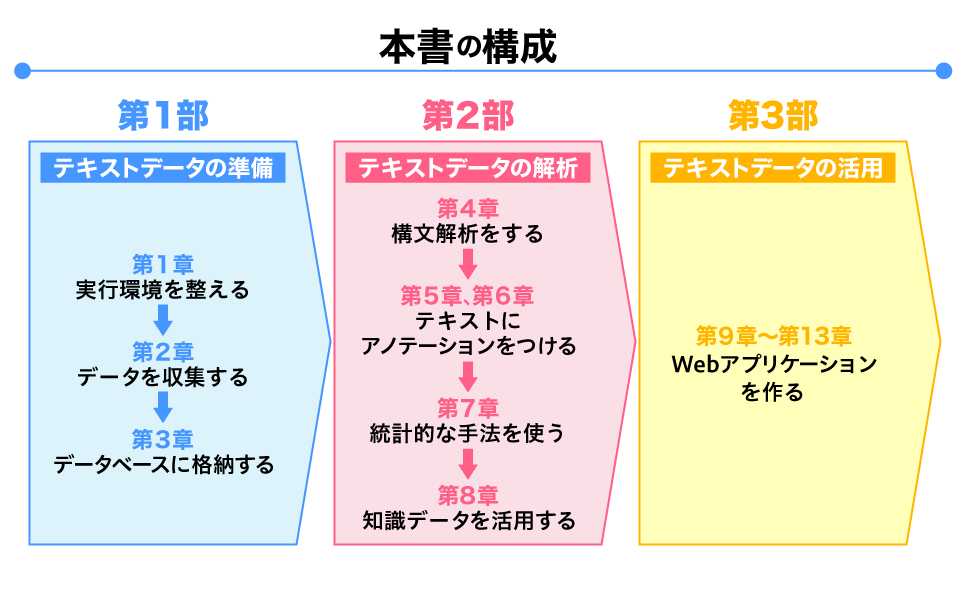
本書の構成としては大きく2つの部に分かれており、
それぞれ以下のような内容を解説しています。
第1部:データの準備
●テキストデータの収集
●データベースへの格納
●検索エンジンへの登録
第2部:データの解析
●文法構造を調べる
●意味づけ
●知識データとの連係
全13章を順に追いながらWebアプリケーションを作っていくことで、
自然言語処理に関連するさまざまなテーマを学ぶことができます。

本書は、Pythonでのプログラミング経験がある人が、各種オープンソースソフトウェア(OSS)やライブラリを利用して、自然言語処理を行うWebアプリケーションを作って動かし、 自然言語処理を体験するための書籍です。またその中で、自然言語処理に関連するさまざまな概念や手法、簡単な理論についても学ぶことができ、本格的な学習の前段階としても最適です。
第0章 自然言語処理とは
第1部 データを準備しよう
第1章 実行環境を整えよう
1.1 実行環境の概要
1.2 実行環境の構成
1.3 Windows 10にUbuntuをインストールする
1.4 Linuxコマンドの使い方
1.5 Ubuntuへのソフトウェアのインストール方法
1.6 Pythonプログラムを実行してみる
第2章 テキストデータを収集しよう
2.1 データ収集とは
2.2 Webページのスクレイピング
2.3 テキストデータを抽出する
2.4 テキストデータのクレンジング
2.5 データ収集のプログラム
第3章 データベースに格納しよう
3.1 データベースを使った検索エンジン
3.2 データベースと検索エンジンの用途
3.3 データベースを使ってみる
3.4 Solrの設定とデータ登録
3.5 Solrを使った検索
第2部 テキストデータを解析しよう
第4章 構文解析をしよう
4.1 構文解析とは
4.2 構文解析の用途
4.3 係り受け構造とは
4.4 CaboChaのセットアップ
4.5 PythonからCaboChaを呼び出そう
4.6 係り受け構造の解析結果のSQLiteへの格納
第5章 テキストにアノテーションを付ける
5.1 アノテーションとは
5.2 アノテーションの用途
5.3 アノテーションのデータ構造
5.4 正規表現のパターンによるテキストデータの解析
5.5 精度指標:RecallとPrecision
5.6 アノテーションのSQLiteへの格納
5.7 正規表現の改良
5.8 チャンクを使わない抽出アルゴリズムを考える
第6章 アノテーションを可視化する
6.1 アノテーションを表示するWebアプリ
6.2 アノテーションを可視化する必要性
6.3 アノテーションツールbrat
6.4 Webアプリケーション
6.5 bratをWebアプリケーションに組み込もう
6.6 SQLiteからアノテーションを取得して表示する
第7章 単語の頻度を数えよう
7.1 テキストマイニングと単語の頻度
7.2 統計的手法の用途
7.3 単語の重要度とTF-IDF
7.4 文書間の類似度
7.5 言語モデルとN-gramモデル
7.6 クラスタリングとLDA
第8章 知識データを活用しよう
8.1 知識データと辞書
8.2 エンティティ
8.3 知識データを活用することでできること
8.4 SPARQLによるDBpediaからの情報の呼び出し
8.5 WordNetからの同義語・上位語の取得
8.6 Word2Vecを用いた類語の取得
第3部 テキストデータを活用するWebアプリケーションを作ろう
第9章 テキストを検索しよう
9.1 Solrを使った検索Webアプリケーション
9.2 検索の用途
9.3 転置インデックス
9.4 プログラムからのSolrの検索
9.5 Solrへのアノテーションデータの登録
9.6 検索結果のWebアプリケーションでの表示
9.7 検索時の同義語展開
9.8 アノテーションでの検索
第10章 テキストを分類しよう
10.1 テキスト分類とは
10.2 テキスト分類の用途
10.3 特徴量と特徴量抽出
10.4 ルールベースによるテキスト分類
10.5 教師あり学習によるテキスト分類
10.6 ディープラーニングによるテキスト分類
10.7 分類結果のWebアプリケーションでの表示
第11章 評判分析をしよう
11.1 評判分析とは
11.2 評判分析技術の用途
11.3 辞書を用いた特徴量抽出
11.4 TRIEを用いた辞書内語句マッチ
11.5 教師あり学習による評判分析
11.6 評判分析の結果を表示するWebアプリケーション
第12章 テキストからの情報抽出
12.1 情報抽出とは
12.2 情報抽出技術の用途
12.3 関係のアノテーション
12.4 正規表現を用いた関係抽出
12.5 係り受け構造を用いた関係抽出
12.6 抽出した関係をSolrに登録
12.7 抽出した関係を表示するWebアプリケーション
第13章 系列ラベリングに挑戦しよう
13.1 系列ラベリングとその特徴
13.2 系列ラベリングの用途
13.3 CRF(条件付き確率場)
13.4 系列ラベリング用の学習データ
13.5 CRF++を用いた学習
13.6 CRF++の出力のアノテーションへの変換
13.7 CRF++で付けたアノテーションをSolrで検索する
付録
A.1 Wikipediaのダンプデータを使う
A.2 PDF、Wordファイル、Excelファイルを使う
na さん
2021-11-19
検索エンジン作成までの大体の概念はわかった。 ソースコードもあって具体イメージ掴めて、サラッと読めて○。 ただ利用技術がちょっと古めだったりしたから、そこは別途勉強したい。

2024年にSEshopで人気だった本を20冊ご紹介!IT技術、生成AI活用、マネジメント本など

翔泳社のプログラミング書籍の中から、入門・初級者向けの書籍をピックアップ!

【エンジニア必携特集】開発現場で使える!ITエンジニアの業務に役立つ書籍を一挙ご紹介

ライティングのスキルアップにおすすめの本。Webライティングやコピーライティングなど
毎日をもっと楽しく、充実させる手帳・ノートの活用術書をご紹介

第二種電気工事士、電験3種など、電気工事技術者関連の資格参考書はこちら
お気に入りに登録すると、気になる商品ページにすばやくアクセスできます。ご利用にはログインが必要です。











